Processing Data with Parallel Computing
Avid developer
It's been about half a year since I last sat down to gather my thoughts and share some key software workarounds through a blog. However, just last week, I stumbled upon a significant discovery while seeding data into my Britelink database. The processes I've been undertaking were quite long and boring lol 🤣. Here's the rundown - gathering and standardizing data for interoperability, merging the data into raw XML, then writing Python scripts to refine the data, and finally converting it into a CSV that I can export into and merge with my MySQL database - I bet you can guess what I discovered - it was inefficient.
I couldn't shake off the feeling of frustration caused by the sluggishness of the processes, particularly during the data seeding phase—the worst script took three days to complete processing a 2MB CSV data file.
So, this is one of the initial scripts I had been running. At first, I thought it got the job done efficiently. But looking at it now, it's almost embarrassing how inefficient it was.
const fs = require("fs");
const csv = require("csv-parser");
const { PrismaClient } = require("@prisma/client");
const prisma = new PrismaClient();
const path = require("path");
const csvFilePath = path.join(__dirname, "..", "..", "public", "drugInt.csv");
async function processDrugInteractions(row) {
console.log(`Processing interactions for: ${row["Drug Name"]}`);
try {
const mainDrug = await prisma.drug.findFirst({
where: {
OR: [
{ tradeName: row["Drug Name"] },
{ genericName: row["Drug Name"] },
],
},
});
if (!mainDrug) {
console.log(`Main drug not found: ${row["Drug Name"]}. Skipping...`);
return;
}
const interactions = row["Interactions"].split(" | ");
for (const interaction of interactions) {
console.log(interaction);
const [interactingDrugName, description] = interaction.split(": ");
let interactingDrug = await prisma.drug.findFirst({
where: {
OR: [
{ tradeName: interactingDrugName },
{ genericName: interactingDrugName },
],
},
});
if (!interactingDrug) {
interactingDrug = await prisma.drug.create({
data: {
tradeName: interactingDrugName,
genericName: interactingDrugName,
},
});
}
const drugInteraction = await prisma.drugInteraction.create({
data: {
description,
},
});
await prisma.drugToInteraction.upsert({
where: {
drugId_interactionId: {
drugId: mainDrug.id,
interactionId: drugInteraction.id,
},
},
update: {},
create: {
drug: { connect: { id: mainDrug.id } },
interaction: { connect: { id: drugInteraction.id } },
},
});
}
console.log(`Finished processing interactions for: ${row["Drug Name"]}`);
} catch (error) {
console.error(
`Error processing interactions for ${row["Drug Name"]}:`,
error
);
}
}
async function createReadStreamAndProcessInteractions(filePath) {
const interactionsData = [];
fs.createReadStream(filePath)
.pipe(csv())
.on("data", (row) => interactionsData.push(row))
.on("end", async () => {
for (const row of interactionsData) {
await processDrugInteractions(row);
}
await prisma.$disconnect();
console.log("Interaction processing completed.");
})
.on("error", (error) => {
console.error("Error reading CSV file:", error);
prisma.$disconnect();
});
}
createReadStreamAndProcessInteractions(csvFilePath).catch(async (error) => {
console.error("Error during the interaction processing:", error);
await prisma.$disconnect();
});
Inefficient I know for sure! - But hey, these things happen, right? Let's review just how inefficient it was.
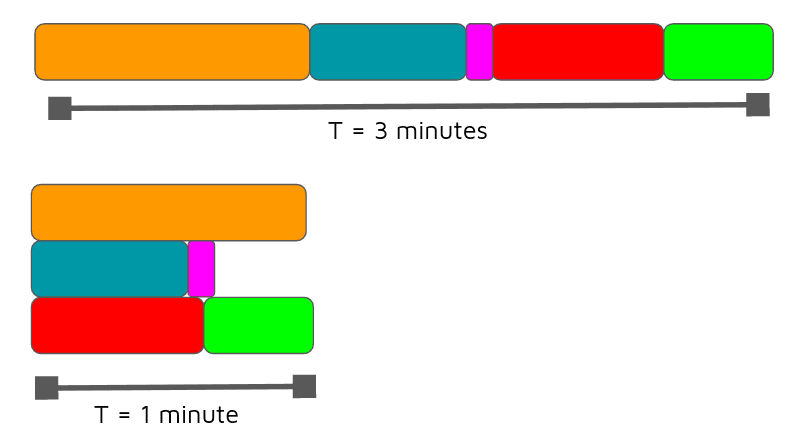
Sequential Processing Overhead
The script employed a highly sequential approach, handling each drug interaction row from the CSV one at a time without leveraging concurrent processing. The function processDrugInteractions operated in a loop where it waited for each drug interaction to be processed before moving to the next one. Here’s the section of the code that highlights this issue:
for (const row of interactionsData) {
await processDrugInteractions(row);
}
Each await in this loop forced the script to complete processing of the current interaction before starting the next, which drastically increased the execution time when dealing with large datasets. so you can see this pattern missed out on potential performance gains that could be achieved through parallel processing techniques such as Promise.all().
Synchronous File Reading
Another critical inefficiency arose from how the script read the CSV file. Although it used streams, which are typically used for handling data asynchronously and efficiently, it collected all data first and then processed it:
fs.createReadStream(filePath)
.pipe(csv())
.on("data", (row) => interactionsData.push(row))
.on("end", async () => {
for (const row of interactionsData) {
await processDrugInteractions(row);
}
});
This method taxed the streaming by loading all data into memory before processing, which led to high memory usage and slow processing for large files.
Optimization
So, after I noticed how this inefficiency was straining my database's RAM and row reads, I wanted a better solution. It occurred to me that instead of taking the time to process one row, why not process two or more rows simultaneously? So, yes, I wrote some code to do parallel processing—instead of handling each interaction sequentially, I used Promise.all() to manage multiple interactions at the same time. The script became complex, and I realized that I was reinventing the wheel. Often in Node.js or JavaScript, there is an npm package that solves your problem. So, I went on to look for something similar and found the async library.
Here is how my script transformed to using the library and significantly improved the speed
const fs = require("fs");
const csv = require("csv-parser");
const asyncLib = require("async");
const { PrismaClient } = require("@prisma/client");
const prisma = new PrismaClient();
const path = require("path");
const csvFilePath = path.join(__dirname, "..", "..", "public", "drugInt.csv");
async function processDrugInteractions(row) {
console.log(`Processing interactions for: ${row["Drug Name"]}`);
try {
const mainDrug = await prisma.drug.findFirst({
where: {
OR: [
{ tradeName: row["Drug Name"] },
{ genericName: row["Drug Name"] },
],
},
});
if (!mainDrug) {
console.log(`Main drug not found: ${row["Drug Name"]}. Skipping...`);
return;
}
const interactions = row["Interactions"].split(" | ");
for (const interaction of interactions) {
console.log(interaction);
const [interactingDrugName, description] = interaction.split(": ");
let interactingDrug = await prisma.drug.findFirst({
where: {
OR: [
{ tradeName: interactingDrugName },
{ genericName: interactingDrugName },
],
},
});
if (!interactingDrug) {
// Optionally create the interacting drug if it doesn't exist
interactingDrug = await prisma.drug.create({
data: {
tradeName: interactingDrugName,
genericName: interactingDrugName,
},
});
}
const drugInteraction = await prisma.drugInteraction.create({
data: {
description,
},
});
await prisma.drugToInteraction.upsert({
where: {
drugId_interactionId: {
drugId: mainDrug.id,
interactionId: drugInteraction.id,
},
},
update: {},
create: {
drug: { connect: { id: mainDrug.id } },
interaction: { connect: { id: drugInteraction.id } },
},
});
}
console.log(`Finished processing interactions for: ${row["Drug Name"]}`);
} catch (error) {
console.error(
`Error processing interactions for ${row["Drug Name"]}:`,
error
);
}
}
const queue = asyncLib.queue((task, done) => {
processDrugInteractions(task)
.then(() => done())
.catch((error) => {
console.error("Error processing task:", error);
done(error);
});
}, 10);
// Once all tasks in the queue have been processed
queue.drain(() => {
console.log("All drug interactions have been processed.");
prisma
.$disconnect()
.then(() => console.log("Disconnected from the database."));
});
function createReadStreamAndProcessInteractions(filePath) {
fs.createReadStream(filePath)
.pipe(csv())
.on("data", (row) => {
queue.push(row); // Push each row into the queue for processing
})
.on("end", () => {
console.log(
"CSV file read complete. Waiting for remaining tasks to finish..."
);
})
.on("error", (error) => {
console.error("Error reading CSV file:", error);
prisma.$disconnect();
});
}
createReadStreamAndProcessInteractions(csvFilePath);
Transition to Async Queue
The inclusion of the async library allowed me to employ its queue functionality, enabling a more controlled approach to parallel processing. By defining a concurrency level, I could now process several drug interactions simultaneously without overwhelming the database, thus striking the perfect balance between speed and stability. Here's how i implemented the queue:
const queue = asyncLib.queue((task, done) => {
processDrugInteractions(task)
.then(() => done())
.catch((error) => {
console.error("Error processing task:", error);
done(error);
});
}, 10);
The queue processes up to 10 tasks concurrently. Each task represents the processing of drug interactions for a single row from the CSV file. This method significantly reduced processing time while maintaining the integrity of my database operations.
Efficient Reading and Queueing
The integration of the async library also refined how data from the CSV file was handled. By pushing each row into the queue as soon as it was read, the script minimized memory usage and reduced idle time for the database connections. This approach ensured that the processing of drug interactions began immediately, leveraging the full potential of asynchronous operations in Node.js:
fs.createReadStream(filePath)
.pipe(csv())
.on("data", (row) => {
queue.push(row); // Push each row into the queue for processing
});
I think this method leaps forward in efficiency, utilizing streams for their intended purpose—processing data on the fly and minimizing resource consumption.
Conclusion
I recommend trying it when you're dealing with large datasets. Implemented the right way, parallel processing can speed up your operations and reduce resource consumption.